안녕하세요.
오늘은 파이썬을 이용해서
구글 이미지 검색 결과물들을
자동으로 다운받아주는 프로그램을 만들어보겠습니다.
간단하게 설명드리자면
1. 아나콘다를 설치해 가상환경에 필요한 버전의 파이썬과 라이브러리를 설치합니다.
2. 셀레니움 라이브러리를 사용하기 위해 크롬 드라이버를 설치해줍니다.
3. 파이썬 코드를 활용해 구글 이미지 검색 결과를 다운받습니다.
순서로 진행하겠습니다.
1. 아나콘다 가상환경 만들어주기
우선 아래 글을 참고하여 아나콘다를 설치해줍니다.
2019.12.22 - [코딩/파이썬] - 비전공자의 코딩 독학 - 파이썬[8] 아나콘다 설치 및 사용방법
비전공자의 코딩 독학 - 파이썬[8] 아나콘다 설치 및 사용방법
안녕하세요. 오늘의 파이썬 코딩 독학 주제는 아나콘다 설치 및 사용방법 입니다. 1. 아나콘다란 ? 파이썬의 배포판중 하나로써 여러가지 라이브러리를 모아놓은 플랫폼입니다. 라이브러리를
bebutae.tistory.com
설치를 다 하셨으면 파워쉘이나 CMD창을 열고 아래 명령어를 따라해주세요.
*파워쉘은 [Win + x] - [a]를 눌러주시면 켜집니다.
//crawler라는 가상환경을 만들어줍니다.
conda create -n crawler anaconda
//만들어둔 crawler 가상환경을 활성화합니다.
conda activate crawler
//가상환경에 파이썬을 설치합니다.
conda install python=3.7
//가상환경에 selenium라이브러리를 설치합니다.
conda install selenium
//가상환경을 비활성화시킵니다.
conda deactivate
2. 크롬 드라이버 다운받기
셀레니움은 웹드라이버라는 기능을 사용하는데,
이 웹드라이버가 웹 크롤링을 하기 위한 기능입니다.
그리고 웹드라이버를 정상적으로 사용하기 위해서는
웹브라우저에 맞는 드라이버 파일이 필요합니다.
우리는 크롬 브라우저를 사용할거기때문에
크롬 드라이버를 다운받아보겠습니다.
크롬 드라이버를 다운받기전에 크롬 버전부터 확인해볼게요.
크롬창 우측 상단을 보면 점 세개가 세로로 찍혀있는 버튼이 보입니다.

요렇게 생겼는데, 이걸 눌러주세요.
그럼 아래와 같이 창이 뜨고, 여기서 [도움말] - [Chrome 정보]를 눌러줍니다.

그럼이렇게 크롬 버전을 확인하실 수 있습니다.

자 이제 아래 링크에서
본인의 크롬 브라우저 버전에 맞는
크롬 드라이버를 다운받아줍니다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 101, please download ChromeDriver 101.0.4951.15 If you are using Chrome version 100, please download ChromeDriver 100.0.4896.60 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 F
chromedriver.chromium.org
저는 99.04744.84 버전이니까 99.04844.51 버전을 다운받아줄거예요.
다운받길 원하는 버전을 눌러줍니다.

그럼 아래와 같은 창이 뜨는데,
여기서 본인의 운영체제에 맞는 버전을 다운받아줍니다.

다운로드가 완료되셨다면, 본인의 작업 공간에 압축을 풀어줍니다.
저는 바탕화면의 crawling폴더에 압축을 풀어주었습니다.

3. 파이썬 코드
파이썬 전체 코드입니다.
주석으로 간략한 설명을 붙였습니다.
# 필요한 라이브러리 리스트
# 핵심이 되는 webdriver, keys
# 이미지 다운로드 시간을 나타낼 time
# 경로 지정에 필요한 os
# 셀레니움이 가져온 URL의 이미지를 다운받아줄 urllib.request
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os
# 디렉토리 생성 함수
def createDir(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print("Error: Failed to create directory.")
# 이미지 크롤링 함수 만들기
def crawl(keyWord):
# 크롬 드라이버 경로
whereCD = 'C:/Users/Bebsae-work/Desktop/crawling/chromedriver'
driver = webdriver.Chrome(whereCD)
# 구글 이미지 검색 URL로 접속
driver.get('https://www.google.co.kr/imghp?hl=ko')
print('구글 이미지 검색 진입')
# 검색창 선택, 검색어 입력, 검색
Select = driver.find_element_by_name("q")
Select.send_keys(keyWord)
Select.send_keys(Keys.RETURN)
print('검색 시작')
# 스크롤 대기 시간 설정
PAUSE = 1
# 크롬 브라우저 창의 높이를 계산
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 크롬 브라우저 창의 끝까지 스크롤을 내림
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 페이지 로딩 대기
time.sleep(PAUSE)
# 새로 스크롤한 높이와 기존에 스크롤한 높이를 비교
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
# 만약 "결과더보기" 버튼이 나오면 눌러줌
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
print('스크롤 완료')
# 구글 이미지 검색결과 썸네일의 class name은 img.rg_i.Q4LuWd
# 해당 class name을 가진 모든 요소를 imgs로 불러옴
# 불러온 이미지를 저장할 경로를 설정
imgs = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
dir = "./" + keyWord
# 디렉터리 생성 함수 실행
createDir(dir)
print('디렉터리 생성')
print('다운로드시작')
count = 1
for img in imgs:
try:
img.click()
# 시간을 읽어온다
start = time.time()
time.sleep(2)
# 큰 이미지를 선택하여 "src" 속성을 받아옴
imgURL = driver.find_element_by_xpath(
'//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img').get_attribute(
"src")
# keyWord 폴더에 keyWord+숫자.jpg 파일로 저장됨
path = "./" + keyWord
urllib.request.urlretrieve(imgURL, path + "/" + keyWord + str(count) + ".jpg")
print(keyWord + str(count) + " 다운로드 중...다운로드 시간:" + str(time.time() - start)[:5] + '초')
count = count + 1
# 다운받은 이미지가 200장을 넘으면 종료
if count >= 200:
break
except:
pass
driver.close()
# 검색어 입력받기
word = input("검색어:")
Searchs = [word]
for Search in Searchs:
crawl(Search)
4. 코드 분석
(1) 라이브러리
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os우선 필요한 라이브러리들을 임포트합니다.
selenium에서 크롤링에 필수적인 webdriver와 keys를 가져옵니다.
webdriver는 크롬 브라우저를 제어하는 라이브러리이고,
keys는 키보드 입력을 소프트웨어적으로 구현해주는 라이브러리입니다.
time은 다운로드 시간을 측정하기 위한 라이브러리이며 필수 라이브러리는 아닙니다.
*시간 체크가 필요없으시다면 코드를 다음과 같이 변경해주세요
print(keyWord + str(count) + " 다운로드 중...다운로드 시간:" + str(time.time() - start)[:5] + '초')
를 아래와 같이 변경합니다.
print(keyWord + str(count) + " 다운로드 중...")
urllib.request는 URL을 열어줍니다.
os는 디렉터리 생성 등 파일 경로 등을 제어할때 사용합니다.
(2) 폴더 생성하는 함수 만들기
def createDir(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print("Error: Failed to create directory.")createDir라는 이름을 가지는 함수를 만들어줍니다.
os 라이브러리를 이용하여 생성할 폴더가 현재 경로에 존재하지 않는다면 폴더를 만들어줍니다.
만약 오류가 발생한다면 에러 메시지를 출력합니다.
(3) 이미지 크롤링 함수 만들기
def crawl(keyWord):이미지 크롤링을 진행하기 위해 crawl이라는 이름의 함수를 만들고
keyWord라는 변수를 이용해 입력받은 검색어를 함수에 넘겨줄겁니다.
whereCD = 'C:/Users/Desktop/crawling/chromedriver'
driver = webdriver.Chrome(whereCD)
우선 크롬드라이버가 위치한 경로를 지정해줍니다.
whereCD = '여기에 크롬드라이버를 저장한 폴더의 경로를 적어줍니다.'
저는 바탕화면의 crawling 폴더에 넣어뒀으니 해당 경로를 지정해주었습니다.
이후 웹 드라이버를 실행시켜 크롬창을 열어줍니다.
driver.get('https://www.google.co.kr/imghp?hl=ko')
print('구글 이미지 검색 진입')구글 이미지검색 주소로 접속합니다.
print함수를 이용해 진행상황을 체크해줍니다.
Select = driver.find_element_by_name("q")
Select.send_keys(keyWord)
Select.send_keys(Keys.RETURN)
print('검색 시작')이제 name 속성으로 구글 검색창에 접근해줍니다.
개발자도구로 구글 이미지 검색 페이지의 검색창의 name 속성은 "q"인것을 확인할 수 있습니다.
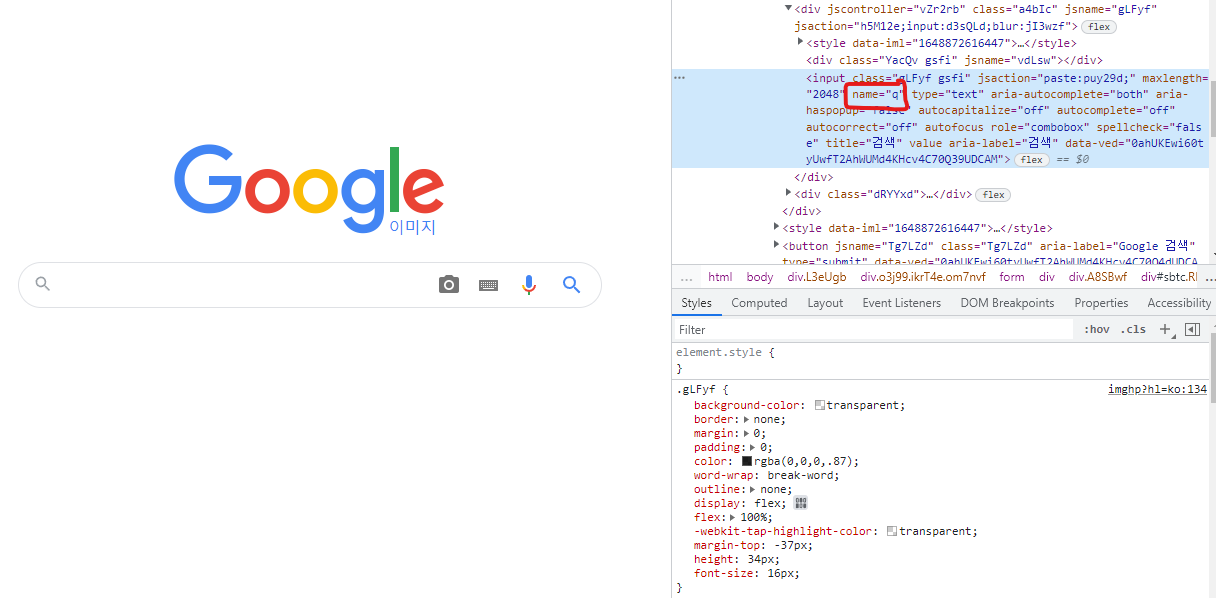
이후 검색창에 검색할 내용을 넣습니다.
마지막으로 keys 함수를 이용해 엔터키를 눌러 검색을 시작합니다.
PAUSE = 1중간중간 페이지 로딩을 기다려야하므로 변수 PAUSE에 대기시간도 넣어줍니다.
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(PAUSE)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
print('스크롤 완료')다음은 페이지를 스크롤하는 코드입니다.
execute_script함수를 사용하면 자바스크립트 코드를 사용할 수 있습니다.
이 기능을 활용해서 열려있는 크롬 브라우저 창의 높이를 계산하고,
해당 창의 가장 아랫부분까지 스크롤합니다.
time.sleep함수를 이용해 페이지 로딩을 대기하고,
새로 스크롤한 높이와 기존에 스크롤한 높이를 비교하여
스크롤한 높이가 같아지면 스크롤을 멈춥니다.
이때 만약 "결과더보기" 버튼이 나오면 눌러주도록 합니다.
imgs = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")이제 검색결과물들을 선택해줘야하는데요
개발자도구를 통해서 확인해보면 이미지들은 .rg_i.Q4LuWd라는 클래스로 특정되어있습니다.

dir = "./" + keyWord
createDir(dir)
print('디렉터리 생성')
print('다운로드시작')이제 검색 결과를 저장할 폴더를 만들어줍니다.
dir 변수에 입력받은 검색어와 경로를 결합한 값을 넣어줍니다.
dir 변수는 createDir 함수에 넣어지고,
createDir 함수에 의해
입력받은 검색어를 폴더명으로 갖는 폴더를 만들게 됩니다.
count = 1
for img in imgs:
try:
img.click()
start = time.time()
time.sleep(2)
imgURL = driver.find_element_by_xpath(
'//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img').get_attribute(
"src")썸네일 이미지를 클릭하고, 로딩 시간을 기다린 후
크게 뜨는 이미지의 div태그에 붙은 id를 모두 불러옵니다.

path = "./" + keyWord
urllib.request.urlretrieve(imgURL, path + "/" + keyWord + str(count) + ".jpg")
print(keyWord + str(count) + " 다운로드 중...다운로드 시간:" + str(time.time() - start)[:5] + '초')
count = count + 1
if count >= 200:
break
except:
pass이제 경로값을 입력받은 후,
파일명을 지정해서 이미지를 저장해줍니다.
str(count)를 이용해서 저장되는 이미지에 번호도 붙여줄게요.
그리고 저장되는 이미지가 200장을 넘으면 멈춥니다.
driver.close()작업이 끝났으니 웹브라우저를 종료해줍니다.
word = input("검색어:")
Searchs = [word]
for Search in Searchs:
crawl(Search)마지막으로 검색어를 입력받는 코드를 작성해줍니다.
5. 결과 확인
코드를 실행시키면

이렇게 검색어를 입력받는데, 저는 댕댕이를 검색해볼게요.
엔터키로 검색어를 입력하면

요렇게 크롬 브라우저가 켜지면서 이미지 크롤링이 시작됩니다.

진행과정을 print 함수로 찍어놓았고,
다운로드 시간이 측정되면서 다운로드가 진행됩니다.

다운로드가 시작되면 이렇게 댕댕이 폴더가 만들어지고,

댕댕이1.jpg, 댕댕이2.jpg, ...
요렇게 번호가 붙은 이미지 파일들이 다운로드됩니다.
'코딩 > 파이썬' 카테고리의 다른 글
| 파이썬 - for 문 사용하는 방법 (0) | 2022.05.23 |
|---|---|
| 파이썬으로 아이디 기반 추첨 프로그램 만들기 (0) | 2022.05.09 |
| 파이썬 - 파일 확장자 한번에 변경하기 (0) | 2022.04.01 |
| 진입장벽이 가장 낮은 언어, 파이썬 (0) | 2022.01.24 |
| 파이썬[12] - 그래프 그리기 (0) | 2021.04.21 |


